close
Portfolio
Showcase
Invest in IPC
Cloud
Blog
Contacts
Russian
E-commerce store data warehouse
Reviewing legal documents using NLP techniques
Sports prediction software
Looking for correlations and making prediction in e-commerce system
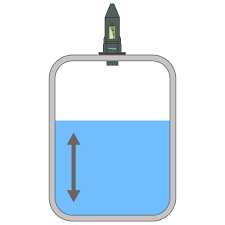
Tank Level Prediction Algorithm