close
Портфолио
Витрина
Инвестируйте в IPC
Облако
Блог
Контакты
English
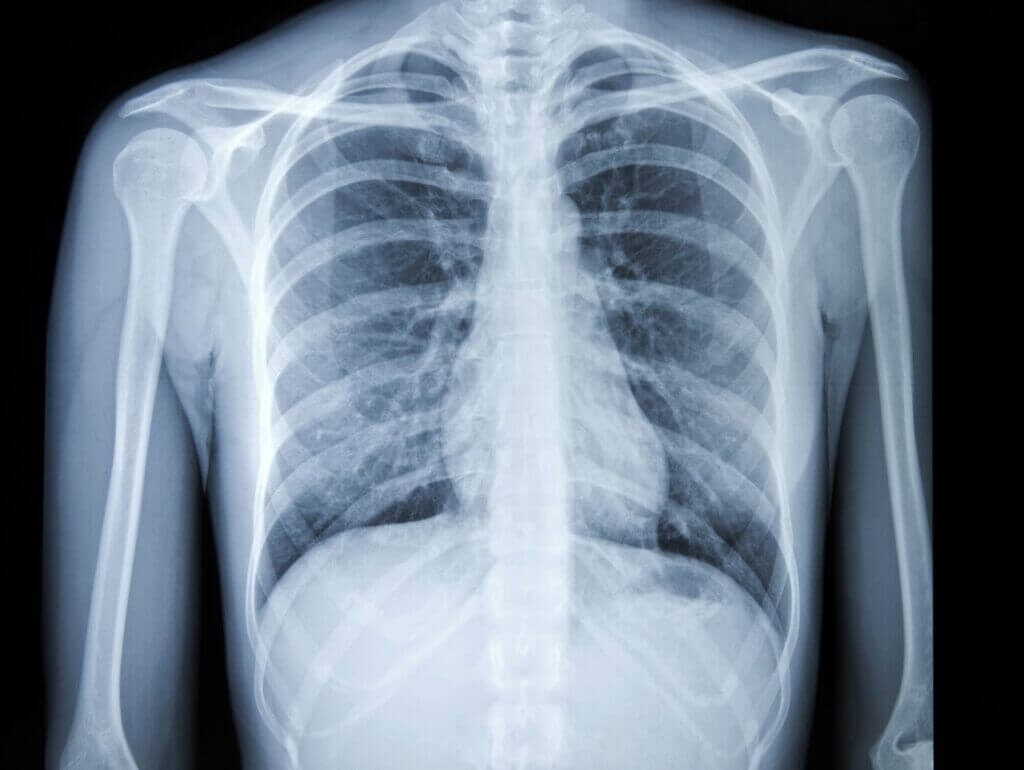
Мета-анализ методов обнаружения рака лёгких на рентгеновских снимках
Магистраль данных для Интернет-Магазина на маркетплейсах
Проверка юридических документов с использованием методов НЛП
Программное обеспечение для спортивных прогнозов
Поиск взаимосвязей и прогнозирование в системе электронной коммерции
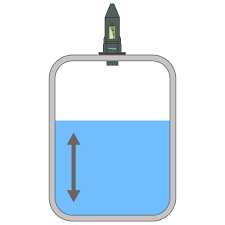
Алгоритм прогнозирования уровня ёмкости